Grok Design Document (Parsing Problem)
Status: Obsolete
(as of 2010-08-16)
Steve Yegge
<[email protected]>
Last modified: 2010-08-16
August 16th, 2010: This document used to be a section in the
Grok Master Design Document. The
issues discussed here are largely obsolete (or resolved). The bottom
line is that Grok doesn't maintain its own analyzers; instead we write
thin wrappers around the compilers/interpreters for each language,
which must provide the information Grok needs in order to be indexable.
Problem #3: Parsing and Name Resolution
Grok will initially support (in this order) JavaScript, Java, Sawzall, C++
and Python. Eventually Grok must support on the order of 50 languages,
including many mixed-mode formats such as PHP, GXP, GWT, XQuery, and other
files that contain nested regions in different languages.
The problem of parsing and resolving 50 languages presents some
difficulties, as one might expect. We have three high-level design
principles for the Grok parsing code, listed here in priority
order:
Insofar as possible, the parsers should use homogenous technology.
We do not want to maintain fifty different parsers written
in different styles and different languages.
We want our code graph to be as complete and accurate as
practical. If developers don't trust the data, they won't use Grok.
The parsing/indexing technology we choose should permit
rapid integration of new languages into Grok.
Design principle #1 mostly rules out the possibility of using the "actual"
parsers for most languages we're indexing. Most official language
implementations do not have parsers that meet Grok's requirements (which
we outline below.) Their parsers are designed to
perform the bare minimum analysis needed for code generation, and they
discard most of the information Grok needs for the index.
There may be a few cases where the language implementer(s) export a usable
parser API, parse-tree format, and symbol-table format, which we could simply
wire up to produce Grok's graph input format. This appears to be the case
for C++ and Java: each has several candidate
frameworks. The Grok team has nearly finished making an API
for JavaScript as well, by painstakingly modifying
Mozilla Rhino's parser and
open-sourcing the changes.
"To confirm your intuition that parsing C++ should be done using the compiler:
I talked with a guy on the C++ compiler team here at Google, and he believes
that it should be "not that hard" to make gcc spit out everything that grok
would want. He also pointed out that even icc (which uses the EDG C++
frontend) has trouble parsing some Google code, so gcc is really the only way
to go for accuracy."
— Kurt Steinkraus
But for most languages, we will most likely have to write our own
parsers and resolvers. Sample parsers are generally easier to come by
than resolvers: for some reason, most parser and parser-framework
implementors lose interest before they finish the name-resolution and
semantic analysis, which is usually at least as much code as the
parser itself.
In a very real sense this means that Grok aims to commoditize tools
support for programming languages. This will be generally beneficial
for programmers worldwide, not just for those of us lucky enough to
work at Google.
Design principle #2 essentially rules out the possibility of
using heuristic-based (typically regular-expression based) parsing,
which is used for indexing most languages by similar indexers such as LXR,
Exuberant CTAGS,
GNU Source-highlight,
and the Semantic
Bovinator. Grok needs to use real parsers and generate accurate symbol tables.
Design Principle #3 implies that we should try to be smart about what
technology we choose. It took months to modify Rhino's parser to meet Grok's
requirements, since in order to open-source it (so we need not maintain the
code) we also had to wire it up to the Rhino code generator. It is not feasible
to take this approach for the next 40 languages.
The following two subsections outline the detailed technical requirements for
Grok parsers, and discuss our ongoing investigation to find the technology that
best satisfies both our design principles and our technical requirements.
Parser Requirements
Grok's parsing and analysis requirements are different from those of
a compiler. In particular, Grok's parsers and indexers must:
Create a syntax tree that faithfully represents the input source.
Many IDE use cases, from syntax highlighting to code reformatting
and refactoring, must be able to recreate or decorate the original
source code. The syntax tree must retain comments and token bounds.
Build and retain per-file and global symbol tables, to
provide hierarchical browsing and identifier cross-linking. Nested
scopes cannot be flattened (as some compilers do): the code graph
must retain the scope chain for every identifier.
Perform static scope analysis for dynamic languages. In
order to provide rich cross-linking, Grok's dynamic-language indexers
must execute what amounts to a partial abstract interpretation of the
program. The problem is undecidable in the general case, but many
languages provide syntactic cues, idiomatic constructs, and extra
metadata (e.g. in the form of type annotations in doc comments) that
can be mined for code-graph information. We have demonstrated this
approach for JavaScript with satisfying initial results.
Attach documentation comments to their declarations,
to provide, for instance, hover-over documentation for identifiers.
Create a table of parse errors and warnings, along with their
best-guess start and end file offsets. Most IDEs
do this already, often producing better error messages and warnings
than the target language's compiler or interpreter.
Never throw exceptions on malformed input: we should produce a
file full of errors, but never fail to index the file.
In short, Grok's indexers have the same requirements as IDE code indexers.
Technology Investigation
The Grok development team is currently investigating parser
technologies. We have implemented parsers for Sawzall, Java and
JavaScript using a variety of approaches, including:
Handwritten recursive-descent parsers, produced by
directly modifying an existing parser to meet the requirements
outlined above.
Haskell
and Parsec,
a parser-combinator library for Haskell.
The Scala language
and a parser-combinator library for Scala; see, for instance,
this
article for an overview and some example code.
The ANTLR parser generator
framework, a reasonably popular ll(k) framework for writing
parsers. ANTLR now has a
published
book explaining its use.
Using third-party IDE-quality parsers, where possible. We modified
the Eclipse "JDT" backend Java compiler to give us its syntax tree
and symbol-table information, and we are also investigating
the suitability of the new Java 6
JavaCompiler
and javax.lang
infrastructure. Similar technologies appear to exist for C++, Python,
and many other languages.
These parsers range from proof-of-concept to production-quality.
Additionally we are looking closely at the
Ocelot
project, which aims to develop a parser framework based on hand-rolled
PEG
(parsing expression grammar) technology.
As of July 20th 2008, we have not yet decided which technology to use
for the "long tail" of languages beyond the "Google core four" (C++, Java,
Python, JavaScript). For the core four languages we may choose to use
different technology from the others, trading off ease of use and
homogeneity for code-graph quality.
We are preparing a competitive analysis of the different parsing
and indexing approaches, and hope to offer a standalone design document
for this particular sub-problem by the end of July 2008. In the interim,
we have production-quality parsers and indexers for Java and JavaScript
that we are using to drive the rest of Grok's development.
Language-specific indexers
The Grok team has spent about 2 months creating indexers for Java and
JavaScript. Here we describe briefly the existing work and touch on
future work.
C++ comprises about 65% of Google's code corpus; Java accounts for about 15%.
Supporting just these two languages gives us 80% coverage, so we feel they
deserve special treatment. We are using open-source compiler technology to
index them: the Parser Problem doesn't apply to them,
since we're not maintaining our own C++ or Java parser technology for Grok.
JavaScript is another special case that we discuss below.
Java

Our Java indexer currently uses the Eclipse Java
Development Tools (JDT) to produce the Java code graph. The JDT Core infrastructure
includes a headless-mode compiler, a Java Document Model API, refactoring support,
a source-code formatter and other modules.
We had to make some custom changes to the JDT compiler for Grok. These
changes involve adding a hook to get to the compiler's IR (intermediate
representation). Although the Eclipse development team has done a good job of
organizing the JDT into standalone jars with separate interfaces, for some
reason they omitted a public interface to the IR. Our modified JDT compiler sources
are checked in to google3/third_party/java/eclipse/google_jdt_compiler/....
We recognize that this situation is non-ideal. This year we hope to
work with the Eclipse team to merge our changes back into Eclipse.
One other option for Java indexing is to use the Java 6
JavaCompiler
interface and javax.lang.* packages, which provide a similar DOM-like
interface to the Java source code IR.
Here is a summary of the pros and cons of the two options:
Eclipse JDT
| Pros |
Cons |
- Complete, accurate, mostly turn-key indexer
- Finds symbols in .jar files
- Robust: designed for IDEs and malformed input
- Yields high-quality error/warning messages
- Supports javadoc indexing
- Supports code refactoring
- Supports code reformatting
|
- Had to modify the compiler source
- Will need further modifications to get symbols from GFS
- Indexing seems slower than it needs to be
|
JavaCompiler + javax.lang.*
| Pros |
Cons |
- Ships with JDK: no 3rd-party dependencies
- Appears to be a complete indexer for source files
|
- Does not find symbols in .jar files
- No refactoring support
- No code formatting support
- Would have to write a lot of wrapper code
|
In a nutshell, Eclipse was the right choice to get a head-start on Grok.
Down the road we may switch to JavaCompiler to give us finer-grained control
over the compiler inputs, outputs, and indexing parallellizability.
Grok does not currently record all the symbol information from the JDT.
We don't capture local variables or formal parameters, primitive-array type
information, and miscellaneous other odds and ends. We will finish the work
to record this information as soon as we have a client that needs it.
JavaScript
We chose JavaScript as one of Grok's first languages for several reasons:
- We wanted a dynamic language to gain experience indexing them
- JavaScript is critical to many teams (6M LOC; ~12M including code in templates)
- JavaScript has generally weak tools support (e.g. no GTags)
Parsing
Our parsing approach was to rewrite Mozilla Rhino parser to produce a strongly
typed AST that reflects the structure of the input source. Here is the
javadoc for the new AST classes.
While rewriting the parser, we made several changes to support Grok
and other parser clients, including:
- Don't rewrite the tree during parsing: keep original code structure
- Optionally record comments
- Record token bounds (file offset and length)
- Record node bounds for every AST node, relative to parent node
- Record start/end positions for all parse errors and warnings
- Improved parse-error recovery: optionally always parse to end of file
Part of the justification for making this change was to help support
the Google JSCompiler
project, which currently uses a very old fork of the Rhino parser with
custom parser changes. We worked with the Rhino maintainers to make sure
our code can be merged back into Rhino so we won't have to support a fork,
as JSCompiler has done.
We have finished modifying the Rhino code generator to use the new parser,
and the code is ready to be merged back into Rhino. The code is checked
in to //depot/google3/third_party/java/rhino/src/mozilla/js/rhino,
which is a CVS snapshot of the Rhino trunk sources that we checked into Perforce.
After we merge the changes back into Rhino we will p4 remove this copy.
Indexing
We produce the JavaScript code graph by indexing on a per-build-target basis.
For each build target We send the transitive closure of the dependencies
(obtained from Blaze) to
a com.devtools.grok.javascript.JsGraphBuilder instance.
A single JsGraphBuilder instance can index approximately 10,000
JavaScript source files in 90 seconds, using about 10 GB RAM. This includes
creating ASTs for every file and merged graph bindings for all files.
Indexing happens in two passes. In the first pass, JavaScript source
files are parsed and partially resolved concurrently using a thread pool.
Each JsParseTask is given a source file and is responsible
for producing:
- the Rhino AST for the file (including error, warnings and comments)
- the file's Bindings (declarations and definitions)
- the file's Associations (usages and certain inter-Binding links)
The flow for a single parse task is shown in the following diagram:
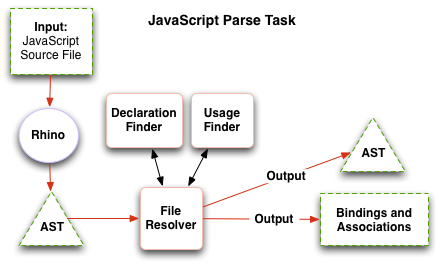
The second pass is a sequential merge and resolution of the symbol
information from all the files. An instance of JsMergeResolver
is responsible for linking bindings form separate files.
For instance, assume file A.js contains the code
var goog = {};
goog.ui = {};
and file B.js contains
goog.ui.Dialog = function() {...}
The JsParseTask for A.js will discover
and record the global symbols goog and goog.ui
in the Bindings list for A.js.
The JsParseTask for B.js sees
the assignment to goog.ui.Dialog and assumes that
goog.ui is an externally defined property. Just
in case, it creates temporary Bindings for goog and
goog.ui, as well as a Binding for goog.ui.Dialog
The JsMergeResolver records the final Bindings
for goog and goog.ui, obtained from
file A.js (because A.js comes first in
the flattened dependency list for the build target). It then
records the Binding goog.ui.Dialog from B.js,
and records appropriate PARENT_SCOPE and PROPERTY Associations
linking goog, goog.ui, and goog.ui.Dialog
in the code graph.
The overall flow of the JavaScript indexing pipeline looks like so:
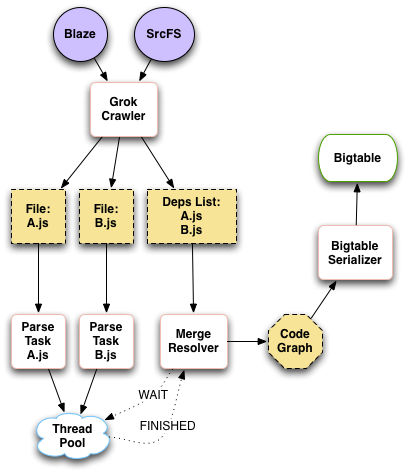
These diagrams are short on detail. The algorithms for discovering
declarations, definitions and usages in JavaScript are fairly
involved. We plan to migrate this material into a separate design
document and expand on it in late Q3.
Much of the pipeline infrastructure we put in place for JavaScript
can be re-used for other custom language indexers.
As of July 20th, our JavaScript indexer could be best described as
"adequate". It does not discover as many declarations and (especially) usages
as we would like. We know how to find more of them; the remaining work
should happen in Q4.
C++

C++ is fourth on our target language list (after Java, JavaScript and
Sawzall), although it will be the top priority for actual Grok support.
We have not yet decided how we will parse and analyze C++, and we
welcome suggestions. We also welcome volunteers!
There are several candidate frameworks for producing the Grok C++ index.
The index data consists of:
- global graph Bindings and Associations
- per-file ASTs
- per-file error and warning diagnostics
- per-file comments
- per-file Bindings and Associations
- the per-project dependency graph (which we get from Blaze)
The leading candidate framework is the
Eclipse C/C++ Development Tooling (CDT),
the C++ counterpart to the JDT we use for indexing Java. The similarity
to the JDT would again give us a big head-start for indexing the code base.
The CDT
FAQ says that from an error parsing point of view, the default
configuration uses (or supports) GCC. It remains to be seen whether
Eclipse will be accurate enough for code written for GCC. Many C++
compilers have trouble parsing code written for other compilers.
However, IDE compilers are designed to accept a broader range of input
than production compilers. So the Eclipse CDT may be able to index
not only our Linux code, but our C++ code bases for Windows and other
platforms.
Python

Python is fifth on the list of target languages for Grok.
(An intern picked Sawzall over Python, which is how it got fifth place.)
We do not yet have a plan for indexing Python. We would prefer
not to write our own parser and resolver. If anyone knows of a framework
or toolkit for parsing and analyzing Python code that meets Grok's
requirements, please
let us know.
It's possible to use any language for plugging a language into
Grok. We have a slight preference for Java-based parsers/analyzers,
because we're likely to use a Java-based parsing technology in the general case.
However, we have a well-defined XML format for the outputs of the indexer,
so any language implementation will be fine.