Contents
who/, b/, go/, corp.google.com) no longer resolve; they’re left in place as part of the artifact. Grok was renamed Kythe in v3 (the open-source release is at kythe.io); the internal Google version is still in active use today. The same architectural thesis inspired Beyang Liu and Quinn Slack to co-found Sourcegraph in 2013. Steve’s 2012 Stanford EECS talk on Grok is a video summary of the project, if forty pages is more than you signed up for. For the full story, see code.html → on yegge.ai.
Status: Up-to-date (as of 2010-08-16)
Steve Yegge <[email protected]> Last modified: 2010-08-16|
Skip TOC
Contents |
|
This is a fairly big design document. To help add context, we use the following icons:
 Unfortunately we don't know CSS very well,
so they're a little ugly. If you have a nice, encapsulated
sidebar-note widget, please let
us know.
Unfortunately we don't know CSS very well,
so they're a little ugly. If you have a nice, encapsulated
sidebar-note widget, please let
us know.
| Icon | Meaning |
|---|---|
 |
We think we have this part under control, although we welcome your ideas. |
|
We have a tentative solution that could probably use improvement. We'd love to hear more opinions. |
 |
We don't really know how to solve this problem yet. We're actively soliciting your educated advice! |
 |
We're deferring this problem for "V2", circa 2009. |
 |
Was iffy, but based on Googler feedback we now have a good solution. |
 |
Needed help, but based on Googler feedback we now have a good solution. |
Please send your comments and feedback about this document or the design to [email protected]. The list is archived, and you are welcome to join. You can also subscribe to [email protected] for very low-volume announcements.
We will include especially useful Googler comments as inline block quotes, like so:
"How'd you make that cool project logo? The Gimp and OmniGraffle, really? Wow!"
— [email protected]
If you prefer that your feedback be anonymous, make sure to tell us, or it may wind up in a blue box.
Grok aims to produce a structured index of the Google code base. The index should be suitable for implementing IDE-like functionality similar to that provided by "rich" editing environments such as Visual Studio, Eclipse or IntelliJ.
HIP
code is out of scope for Grok, largely because nobody on Grok has HIP privileges.
Grok does not aim to provide support for third-party code. It may be possible to adapt Grok to become an adjunct to code-hosting sites such as Google Code, Code Search or Google App Engine, but they are not in scope for the Grok project as of July 2008. Grok is aimed squarely at improving internal Google developer productivity.
Grok will not provide an actual IDE. We will implement a read-only code-navigation tool similar to the interface of koders.com. We will also provide support for IDEs and other clients to get information from Grok's index. We will write the plugins for some set of editors to be determined.
Grok is not a static analysis framework. Grok's
code index is intended to be a database-like repository suitable for retrieving
specific information about individual source files or program elements.
Update 2010-Aug-16:
We have begun adding some support for doing static analysis. For example
we have added the global call graph to the index.
There is widespread interest in having a "fancy" code viewer, which we're calling Grokweb. See, for instance, Deluxe Java Viewer, an ideas-tool submission that proposes something very like Grokweb, except specific to Java. Although Grok will ultimately support interactive use through IDEs, we view Grokweb as an important near-term deliverable for Grok. It will demonstrate some of the capabilities of the Grok code index while solving an immediate productivity need.
Update 2010-Aug-16: Internal Code Search is now the recommended web frontend for browsing Grok. Grokweb will be deprecated once Code Search reaches feature parity with Grokweb. Grok's focus is on integrating with existing clients, not making new ones.
The motivation for Grok is twofold. The first problem is simply one of scale: we have too much code for rich IDEs to index on local machines. Google developers often ask questions on internal mailing lists of the form: "how do I find all the [callers|implementors|subclasses|...] of a given [method|interface|class|...]?"
Grok will address the first problem by extending IDE capabilities to include querying and navigation of the entire code base.The second motivation is that we have N languages (N ~= 30) and M editors (M ~= 10). The product N × M is large enough that editors and IDEs each support only a handful of languages well. Grok addresses this problem by introducing a hub-and-spoke model that reduces the problem to N + M, by providing plug-in frameworks for adding new languages and editors.
Three external projects stand out as being very similar to Grok:
Krugle: a code-search engine similar in many ways to Grok. Krugle offers a commercial product in the form of a tightly controlled black-box appliance. They also provide a free public search engine that indexes over 2 billion lines of open-source code. Krugle does not have an extension framework to let users add languages to the system. They also do not offer cross-linking of identifiers in the source code, so presumably their metadata index is nowhere near as rich as what we're building for Grok. Despite the differences, Krugle is probably the closest thing we've found to Grok's goals.
Koders.com: a structured code index for open-source code. Koders is also very similar to Grok, and even provides IDE plug-ins for Eclipse and Visual Studio. As of July 20th 2008, Koders indexes 766 million lines of open-source code. Google's code base is approximately 250 million lines of code, so the products are similar in both intent and scale. Koders does not support context-specific search, however; an identifier search from a given class does a search of the whole corpus. Overall Koders appears to be a slightly weaker offering than Krugle.
LXR, the Linux Cross-Reference. Provides a searchable, navigable index with identifier cross-linking and per-file lists of declarations and usages. Similar to Koders, but is an open-source indexing framework. See, for instance, lxr.mozilla.org, the LXR index of all Mozilla code. We could use LXR to index our code base, but it is not designed to create a general-purpose IDE backend. Grok will provide LXR-like functionality as a byproduct of its structured index.
Other noteworthy external projects include:
OpenGrok: an open-source LXR clone (in the sense of being a cross-referencer based on Exuberant CTAGS) with a GUI for browsing and a plug-in system. (Note: the name similarity is a coincidence; OpenGrok does not show up in searches for "Grok".)
Pattern Insight: a commercial product for finding code duplication. Should be straightforward to implement this use case by using Grok's code index.
Semmle: a commercial Java/XML indexer and query engine. Their SQL-like query language looks interesting.
Here is a partial survey of related internal work:
GTags:
a service that allows you to jump to a function or variable definition,
find all callers of a particular function, or grep over definitions and
function calls in Google source code.
Grok's code graph and wire protocol are being designed to support context
information unavailable to GTags, such as restricting searches to the context
of the particular class under consideration.
Aug 16 2010: GTags is having scaling and
staffing issues. We are working with the GTags developers to migrate its
functionality into Grok, after which GTags will cease to exist as a separate
indexing pipeline and server cluster.
GSearch: a very popular internal
code-search service. Provides fast regular-expression based searching over many
corpora comprising some 250 million lines of code in over 30 languages. GSearch does
not index hierarchical code structure, which precludes most of the use cases that
Grok aims to solve. It also does not index generated code (Grok will do so).
GSearch is, however, a wonderfully useful tool that will continue to have
a deep impact on developer productivity at Google, even if Grok achieves all
its aims.
Aug 16 2010: GSearch has been effectively
deprecated and replaced by internal Code Search.
Sourcerer: a popular code browser
for google3 that interfaces well with Perforce. It does
not offer the rich identifier cross-linking facilities available
in IDEs and LXR.
Sourcelink: an annotation-based
code-indexing framework that provides the syntax-highlighting and
cross-linking metadata to Sourcerer. Should be able to migrate to using
Grok for its backend.
Aug 16 2010: We have an
alpha-quality demo of this integration, in C++, and are looking
for 20% contributors to complete it.
Ocelot: the beginnings of a PEG- based parser framework that may be useful for Grok's indexing pipeline.
JSearch: a Grokweb-like Java search and navigation tool.
Static Analysis Tools at Google. There is some overlap with Grok in this space, but the static analysis tools do not attempt to provide a structured index of the code for use in IDEs.
This list is not complete. We have met with some twenty teams doing similar work. None of them is making a serious attempt to produce a general-purpose code graph and hierarchical code metadata index suitable for driving IDEs. After some 4 months of work on Grok, we now feel reasonably certain that we are tackling a unique problem space at Google.
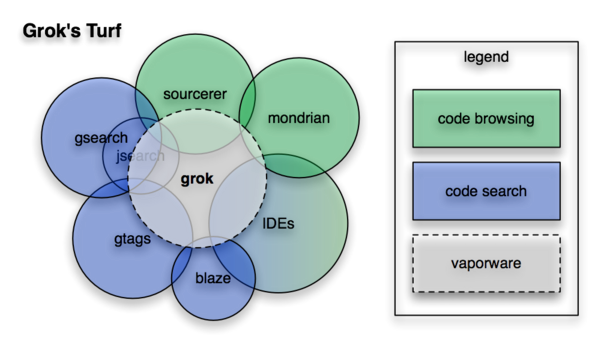
Nonetheless there is some overlap with other Google projects. This diagram illustrates how we see Grok fitting into the landscape of code search and browse technologies at Google. The circle sizes are chosen to make the relative sizes of the overlaps semantically meaningful: for instance, we believe Grok has more overlap with GTags than with Mondrian. Hence the circle sizes themselves are somewhat arbitrary.
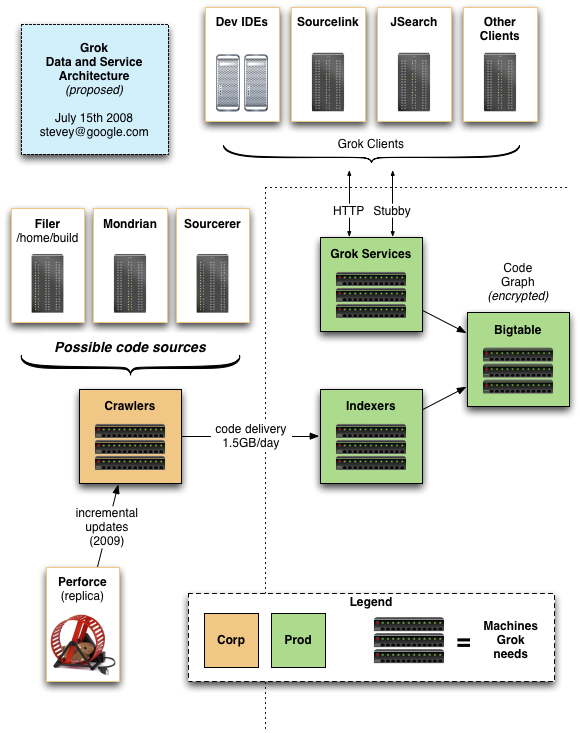
Grok consists of a crawl pipeline, an indexer pipeline, a Bigtable containing the code base index, and a serving cluster.
The crawler(s) fetch the source code from a repository or replica. The indexers are language-specific analyzers that produce graph information. They send the code-graph data to the bigtable, where it is served via HTTP and Stubby to various clients by the Grok Service API layer.
Here is a conceptual diagram of Grok's architecture. There is more detail in the Infrastructure section.
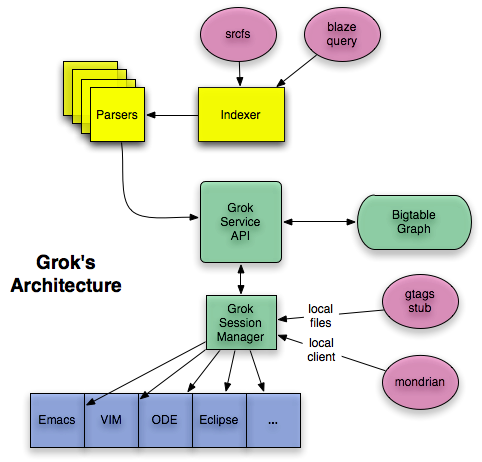
Aug 16 2010: We have been using sstables rather than Bigtable for over a year now.
The diagram is approximate; details may change. For instance, the indexers and some clients may talk directly to the SSTables rather than going through the Grok Service APIs.
The Detailed Design section covers Grok's component subsystems in more detail.
Here we outline the proposed Grok data and service infrastructure.
We are actively soliciting feedback on this proposal. It's important that we get consensus on this architecture early, to avoid having to redo our machine requests several times. We're interested in hearing from all experienced Googlers.
We're also interested to know whether people think less structure (e.g. SSTables) or more structure (e.g. Megastore) would be more appropriate than our proposed Bigtable-based code index.
Some details follow the diagram.
August 16th 2010: Nearly everything in the diagram below is now running in prod, as corp cells no longer exist. The crawl phase (which uses blaze query) still has some components that run on our developer desktops, pending a solution to getting FUSE into prod (http://b/issue?id=1892345). The bug has been open for over a year, so it may not be resolved soon.
The indexers read from srcfs and gfs, and write to sstables in gfs. The rest of the discussion in this section is obsolete.
July 30th 2008: based on lots of SRE feedback, we present the updated diagram here:
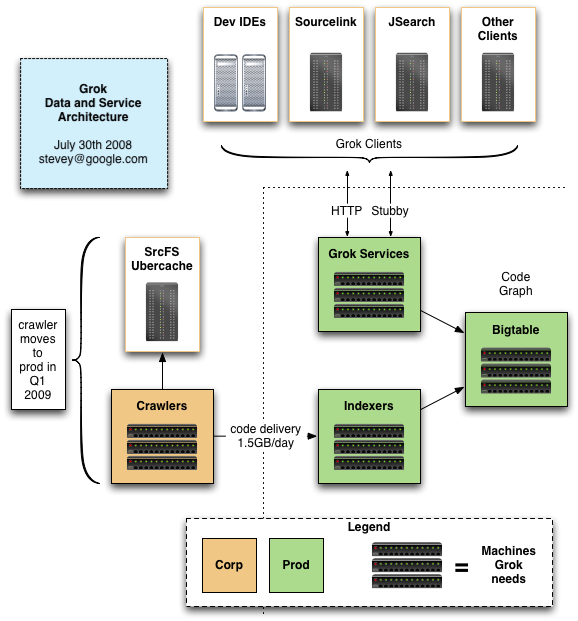
Many people seem to think that even with a new corp data center
coming online, the steady-state of corp clusters is "chronically
oversubscribed". We fear that even with dedicated Borg resources
in corp, Grok would be too slow to use as an IDE backend. If you
have evidence to the contrary, let us know.
We're going to use prod for storing the code, but at least we now know that corp would be just as fast, as a fallback option.
Click here for the old diagram.
The proposed corp/prod split is motivated by two concerns:
If either concern turns out to be non-problematic, then we can modify the proposal to be all-corp or all-prod, respectively, which would simplify both the machine request process and the administration of Grok's Borg jobs.
"The prod-in-corp datacenters/borg clusters are indeed very tight on space. However, if you do in fact get resources, their performance and availability will be exactly as good or bad as a 'real' prod cluster."
— Gabriel Krabbe
To implement this proposal we will need to make three separate machine requests:
a Borg resource allocation in corp
(ep=Ireland, fp=San Jose or up=Atlanta Metronexus)
with access to a filer, srcfs, or some other daily snapshot
of the code.
a Borg resource allocation in prod for our indexing and serving jobs. These are physically distinct process clusters that do not need to communicate, so if necessary we could put them in separate data centers. Ideally they would both reside in the same cluster as our Bigtable.
a physical machine allocation in production for donation to BigtableService
We estimate that the indexers will need to send between 2 and 5 terabytes a day to the Bigtable, so we predict (pending SRE verification) that we will have to run our indexers and BigtableService clusters in the same data center to minimize network congestion. Note, however, that we do not need particularly high-bandwidth connections from the indexers to the Bigtable, since the data stream in over several hours.
July 30th 2008: when the SrcFS ubercache is available in production in our datacenter, we will move the crawling entirely into prod.
The indexers may need to read from the Bigtable for shared symbol information. Or we may use GFS. See Scaling the build for more detail.
Dec 17th 2008: We are migrating away from Bigtable towards using SSTables. As our index is read-only once constructed, SSTables are potentially much faster to access.
If you have questions or concerns about any aspect of this proposal, please let us know so we can make adjustments.
Grok initially sounds pretty easy. ("Hey, if Koders did it...") In practice it is a big, ambitious project with several distinct subdomains, each with its own set of design issues and open problems.
As of July 20th 2008 we are four months into the design and implementation. Only now, as we approach an early demo launch, do we feel we have sufficient understanding of the problems to be able to circulate this preliminary design document.
The following sections can be read independently. We cover the problem domains in "data-flow" order. Here is a brief overview of the domains:
First we fetch (crawl) the code from the repositories and (eventually) developer workstations.
Then we build the code, project by project: just enough to produce input for our indexers (by generating dependencies and building generated files).
Next, we parse and resolve (analyze) the code, producing a symbol table and other artifacts.
Then we index the code, producing a code graph and metadata that is written to our sstables.
We serve the indexed code, over Stubby, HTTP and possibly other protocols, gradually building up a library of service APIs that wrap the sstables.
Finally we display the index, in Grokweb, Code Search, Emacs and other clients.
This decomposition is only one way to view the design and planned growth for Grok. Another view is chronological, in which we first get a read-only viewer (Grokweb) working for one or two languages, and from there begin branching out in several dimensions: more languages, richer indexing for existing languages, support for graph versioning (e.g. for projects on older branches), more editor plug-ins, indexes for more use cases, a query language. Still another view is the network of teams providing inputs and outputs for Grok.
We have chosen to organize this design document with a data-flow focus. Each of the six stages above is outlined briefly here, and each may also acquire a supplemental design document with more detail.
For other views of Grok, please visit the Grok Project Wiki, which will (soon) be populated with up-to-date information about OKRs, customers, deliverables and documentation.
The next six top-level subsections can be read in any order. Feel free to skip any you think are not immediately interesting. Most of the problem domains are largely unsolved, and we are actively seeking feedback from the Google engineering community on how to approach them.
Getting a snapshot of the code poses a set of design problems.
Options include the filers (/home/build), SrcFS,
p4 and subversion depots or replicas, Sourcerer (which has a p4
snapshot), and even Mondrian, which knows how to get unsubmitted code
from developer workstations.
Based on SRE feedback we are eliminating /home/build, P4
and Sourcerer as options.
The consensus seems to be that SrcFS is the way to go.
The SrcFS team is allegedly working on getting an ubercache
set up in prod, which will enable us to jettison all prod-in-corp resource
dependencies from Grok.
"I can hardly begin to describe the problems you'll be facing if you use /home/build - it's not accessible from the corp borg cells, so you'd need to get (real or virtual) dedicated corp servers; it provides a non-consistent view of the depot(s); it's amazingly slow (even within the corp datacentres); it's error-prone (grhat is thankfully no longer a consideration, but even on goobuntu, kerberos tickets need to be refreshed, giving a short but terrible interval during which requests can fail). You really don't want to use it..."
— Gabriel Krabbe
"A diagram shows access to source code coming from /home/build, mondrian, or sourcerer currently; it might be easier to talk to SrcFS ubercaches, since they've already got the machines running in FP grabbing the latest source, and they've solved or are solving nonconf vs. conf, HIP, etc."
— Kurt Steinkraus
"Sourcerer has its own representation of the metadata - viewing files ends up doing a p4 print against a replica on the back side. If you're looking for the file content, you don't want to use sourcerer, better off printing off one of the replicas directly."
— Charles Ballowe
Down the road we want to index in-progress code. For now we are focusing on daily indexes of snapshots of the "head" revision of our code base. Even this simpler use case is problematic for several reasons:
We do know that several projects (notably Mondrian and Forge) have managed to solve this problem, and we're talking to those teams. But as of July 20th 2008 we do not have an official design proposal for where to get the code. July 30th 2008: we'll be using a SrcFS ubercache – initially in corp, but switching to prod when it becomes available there.
We have a preliminary directive from security-team to "use encryption". However, our persistent code graph provides a thoroughly detailed breakdown of every Google source file, indexed in many ways. A simple encryption per-record byte steam encryption scheme doesn't help here.
A related problem is authentication: the Grok service(s) must require the appropriate authentication level for accessing the code, e.g. conf vs. nonconf. (HIP is out of scope for the forseeable future.)
Grok will need a thorough security review. We have had an initial meeting with a Google security architect ([email protected]) to discuss our design, and we have begun a security-specific design document that should be available by end of July 2008.
Dec 17th 2008: We are mimicking gsearch's authentication
strategy for non-web clients. For Grokweb, we are using SSO. We will migrate
to the new SourceProtect service when it becomes production-ready.
Aug 16 2010: We had another security review this summer, and security-team was satisfied with our design and implementation. NOTE: We do not store the source code in the index
We run our indexers and serving clusters in prod data centers (see the Infrastructure section below). This implies that we will have crawlers in corp that send the code (lists of source paths) to indexers in prod. It's only about 2GB of compressed data, as of our latest estimates, so it should be achievable.
Jul 30th 2008: We will have a process in prod-in-corp reading from a SrcFS Ubercache and shipping the code to our prod machines. When a prod SrcFs Ubercache becomes available (projection: late 2008), this entire sub-problem goes away. Suggested by SREs; tentatively accepted by security-team, pending our actual Security Review.
Aug 16 2010: Our crawler runs with BuildRabbit on corp (dev) machines, and we create gfs files containing lists of build targets, the source dependencies (paths to query in srcfs), and any generated files needed by the indexers.
In the medium term we would like to have Grok switch from batch-based updates to incremental updates. Essentially we would need a Perforce trigger that notifies us of new changelists, from which we would compute the transitive closure of files "tainted" by the CL, and re-index those files. There is at least one framework (MillWheel) coming online soon that should help with this problem. We leave the incremental-update problem out of scope for this version of the Grok design document.
"You also show incremental updates coming from a perforce replica in 2009; you might want to talk to the piper guys (http://p/?p=9210), who are currently shooting for a late 2009 launch."
— Kurt Steinkraus
This is probably the hardest sub-problem within crawling/indexing.
Our medium-term (2009) goal is to have Grok know about your Perforce clients and have stateful interactive sessions on a per-client basis. When you use Grok for identifier searches, autocompletion and other tasks, it should know about all the code in your client (including files in your build that have not yet been added to the depot). When appropriate, Grok should restrict your queries to the subset of Google code defined by the transitive closure of your project's BUILD dependencies.
For 2008 we will punt on versioning. Grok will be useful to the extent that your Perforce client is in sync with the repository trunk/head. Grok's accuracy will degrade for older code. We will address versioning in 2009.
This part of our design document is still wide open, and we encourage you to send us feedback if you have ideas or suggestions.
Indexing the code is closely related to the notion of building it. In this section we explore this relationship and discuss the general approach we're taking, along with the known open design issues.
In order to produce "correct" symbol-table and code-graph data for most languages, Grok needs per-project build dependency information.
As a simple example, a JavaScript file may refer to a
global function named addChild. This name is
sufficiently generic that it may be defined as a function in dozens or
even hundreds of unrelated files. In order to winnow the candidate
set, each JavaScript file's external symbol lookup should be
restricted to the set of files being served to that web page.
A second example illustrates that the same basic problem exists even for languages with moderately strong static typing such as Java and C++. In C++, you may have code that depends on different versions of the same third-party library. For any given source file, Grok should generate code-graph data that sends you to the correct library version for identifiers referenced in that file.
Hence, we cannot achieve the best results by indexing the entire google3 code base as one large virtual project. We need to build up the code graph by indexing one project at a time. Each project needs access to the symbols from its dependency transitive closure.
We are using Blaze to get this dependency information. Blaze has a query language for BUILD files. It gives us the flattened dependency graph for each project, which we then reconstitute as an actual graph which we use to orchestrate the operation and interaction of the crawlers and indexers.
Blaze has been outstandingly helpful in getting Grok bootstrapped. There remain some open problems, covered in the following subsections. But for the most part we are convinced that using Blaze for getting dependency information is a "settled" design decision.
Dec 17th 2008: We are also gearing up to use the new TAP service for the dependency bootstrapping problem, circa Q1 2009.
We do not in general need to perform code generation (to produce linkable/runnable artifacts such as .a, .so or .pyc) in order to produce Grok's code index. C++, for instance, can get external symbol information from header files.
The standout exception is Java, where it is standard practice to fetch external symbol information from .jar (or .class) files, because it's faster than re-parsing the source files. This doesn't make much of a difference for a single build. For many builds (see Scaling the build, below) it will be a major machine-utilization win to compile the shared .jar dependencies once apiece.
This means that for Java we need to do code generation. This (along with generated source, next section) is why we often speak of "building" the code in order to index it.
Grok needs to be able to index automatically-generated source code.
For instance, Ads Frontend developers are well aware that you often
need to look in DPL/Pebl code
generated by the DPL compiler. Similarly, it is quite
useful to be able to look at classes generated by the protocol
compiler from .proto definition files. As a general rule, developers
will want their generated code indexed by Grok.
We use Blaze to generate code
from gen* BUILD rules:
genrule,
gengxp and
their ilk. We have an open request to the Blaze team for an option
to stop the build after the gen-rules complete, and we do not anticipate
any difficulties here.
Grok should be able to index code that doesn't build. We need to perform at least partial Blaze builds to get generated source files. However, even when the source is incomplete, Grok will make a best effort to index the code anyway. Note that this design goal places some unusual restrictions on the language analyzers we use.
"A caveat: Blaze will fail and give you no information if the BUILD file is sufficiently wrong, so this approach will most likely tolerate errors in source code but not BUILD files."
— Brian Slesinsky
As a general rule, Grok will strive to be correct and complete, but will prefer to provide degraded information over no information.
The Blaze team has been creating some scripts to help work around broken build files. We should be able to get dependency information for most of the code base even when some BUILD files in the dependency chain fail to parse. We can use this dependency information to index projects even when they cannot be built "normally" by Blaze.
It might be more fruitful to think about ranking rather than confidence. There are all sorts of tricks that search engines use to rank their results, and they often have analogies for code search.
— Brian Slesinsky
This section used to contain a discussion of possible approaches to partitioning the input graph, in an effort to minimize the total work done by the Grok indexers. That discussion has been moved into a separate design document.
Dec 17th 2008: After much deliberation and experimentation, we have opted for sharding the code-base analysis by creating N roughly equal-sized work buckets ("shards"), each containing a number of randomly-selected build targets from the input set such that the buckets have similar file counts.
The downside of this approach is that we analyze and index each
file potentially many times, as a function of how often it is
referenced (transitivitely) by google3 build targets.
The upside is that it is relatively simple to parallelize.
Aug 16th, 2010: We solve the parallel-indexing problem as follows:
We run a batch job every night in borg to index the whole code base.
The crawl phase arbitrarily arranges the build targets into "indexer shards" -- about 1000 shards total, each shard typically analyzing 1000-5000 build targets sequentially.
Each indexer shard attempts to claim the files it is working
on, using a shared ClaimServer. Each file
in google3 is claimed by at most one shard during a
nightly indexing run. A shard analyzes entire build targets, but only
generates the index bindings and associations for files that it has
claimed in each target.
The Java analyzer has special requirements. To avoid having
to recompile and regenerate .class files for every dependency
for every build target, we have a ClassFileServer that acts as
a cache. Only the Java analyzers talk to this server.
The shards write their per-target sstables to local disk. After the last target is analyzed in each shard, a local sstable merger process runs to create a master merged sstable for the whole shard.
After all indexer shards have finished, a master merger creates the global index, which is a set of per-language sstables.
Grok does not yet support incremental indexing. The indexing pipeline is likely to remain batch-oriented until at least mid-2011.
Aug 16th 2010: Moved the original discussion into a separate document. Most of that discussion is obsolete.
As of August 2010, Grok uses the following indexers:
| Language | Resolver | Notes |
|---|---|---|
| C++ | Eclipse CDT | The CDT sucks. We're migrating to clang. |
| Java | Eclipse JDT | We're using an old forked version, because they didn't have an API to their resolver. May be fixed now? |
| JavaScript | JSCompiler | We have more wrapper logic than we want -- it needs to migrate into JSCompiler at some point. |
| Python | Jython's org.python.indexer package |
Written from scratch by a Grok intern (Yin Wang). It is officially part of the open-source Jython distribution. |
| Protocol buffers (.proto) | Google proto compiler | Support implemented by 20% contributors in Hyderabad office |
| Blaze BUILD files | Blaze query | Our first analyzer written in Flume |
As a general rule, we prefer to have the Grok analyzers be thin wrappers around an analyzer owned by the community responsible for the language being analyzed.
This section outlines the design of Grok's code graph.
This
is one of the most stable parts of our design. This section gives
an overview of our language-neutral graph format, which borrows
liberally from the Eclipse JDT format. We have used our format to
represent five languages as of Aug 16 2010; it has proven to be
quite flexible.
Grok builds a graph representing identifiers and their relationships. The graph model is designed to be language-neutral in two ways:
We begin with some term definitions.
| Identifier | A programmer-chosen name for a source code element, such as a variable name or a type name. |
| Symbol | Sometimes used to mean an identifier that Grok records in the graph. |
| AST | (Abstract Syntax Tree) A tree representing the parsed program source. |
| Diagnostic | A compiler error or warning in the indexed source. Includes file position and length. |
| Binding | A node in one of Grok's various graphs. Corresponds to a row. Every Binding has a globally unique URI called a "signature". A Binding can represent any entity. |
| Association | Represents a relationship between two Bindings. In short: a typed, directed graph edge. Associations are columns. |
| Usage | A specific code site (with an associated position and offset) that refers to a Binding. Can be a call, an instantiation, or an uncategorized reference: any name appearing in some syntactic context. |
We intentionally avoid using the terms declaration or definition in the language-neutral Code Graph nomenclature, because these terms have language-specific meanings. In Java they are more or less synonymous, but in C++ and JavaScript they are different: a declaration is the introduction of a name into the symbol table, and a definition assigns the name a definite value. Some languages permit more than one definition for a given declaration.
We use term Binding in the sense of a key/value pair, in which the value is "bound" to the key. All addressable nodes in our code graphs have Bindings. A Binding's locator is its signature, which is used as the row key. A signature must be unique across languages and versions of a file. It should ideally be stable across purely cosmetic code changes such as reformatting. A typical signature might include information about the identifier's repository path, changelist number or other versioning information, program scope, and type.
Most of the Bindings in Grok's index represent program identifier declarations/definitions (also called identifier bindings or symbol bindings). However, the concept of a Binding is broader and more generic: anything we want to be addressable gets a Binding. Grok's index includes a Binding for every source file, a a Binding for every identifier usage site, Binding for every .jar file or other third-party source archive, and a Binding for every BUILD target. The information kept for a Binding depends on its type; for instance:
| Binding Type | Metadata | Data |
|---|---|---|
| Identifier | signature of containing Resource Binding | Associations |
| Resource (a source file or archive) | Compressed file contents, serialized AST | Lists of Bindings, Associations and Diagnostics exported by the Resource |
| BUILD Target | (tbd) | Transitive closure of depend targets |
When we speak of Bindings, we usually mean identifier bindings We will explicitly disambiguate when we mention the other kinds of Bindings.
An Association generally represents a link between two AST nodes. For
instance, the code fragment class B extends A generates the following
bindings and associations:
BB to AA to BA,
representing the physical mention of A in the fragmentAdditionally, if a Binding does not already exist
for A when the fragment is analyzed, a provisional
unresolved Binding is created for it. This provides a place to attach
the EXTENSION association from A to B.
The next section covers the in-memory graph representation in more detail.
Consider the following Java code fragment, split across two
files A.java and B.java. There are four
declarations: A, B, A.foo
and B.foo. This diagram shows the bindings and
associations created for this code. Boxes are bindings, and arrows
are associations.
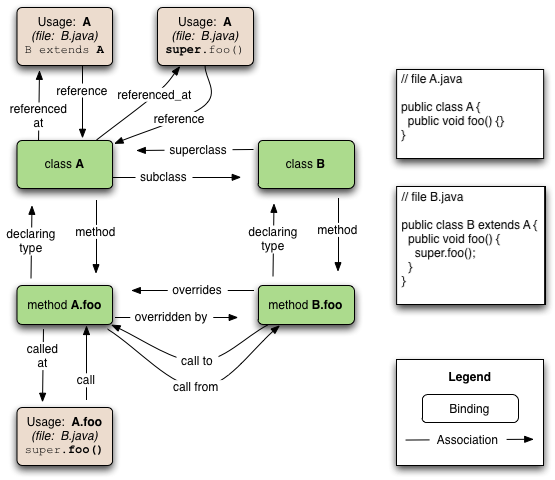
The diagram shows the logical code graph produced from the code. The boxes are the Bindings, and the arrows are the Associations. There are six Bindings and sixteen Associations created for this code.
The Associations are created in matched pairs:
A is the superclass of B, and
B is a subclass of AA.foo is a method of A, and
A is the declaring type of A.fooB.foo is a method of B, and
B is the declaring type of B.fooB.foo overrides A.foo, and
A.foo is overridden by B.fooB.java contains a reference usage of A
(directly, in the extends clause), and
A is referenced at that location in B.java B.java contains a reference usage of A
(indirectly, via the super keyword), and
A is referenced at that location in B.java B.java contains a call usage of A.foo (via the super.foo() invocation), and
A.foo is called at that location in B.java
B.foo calls A.foo (in a location-independent sense), and
A.foo is called by B.foo (also location-independent)The first four pairs of Associations comprise the Grok Type Graph: static, structural type relationships innate to the declarations. Type-graph relationships include pairs like INTERFACE/IMPLEMENTS, SUPERCLASS/SUBCLASS, PROPERTY/PARENT-SCOPE, CONTAINED-METHOD/DECLARING-TYPE, and a few dozen others.
Association pairs 5, 6 and 7 comprise the Grok Reference Graph: links between declarations and code sites that statically name them. A Usage Binding is created for every code site that names an identifier -- these are the tan boxes in the diagram. Usages can be a Reference, Call or Instantiation, and other finer-grained usages distinctions may be introduced over time.
The final pair of associations comprise the Grok Call Graph. The Call Graph is used often enough in static analysis that Grok includes associations between callers and callees directly.
Every Association is a directed arrow between two bindings.
In the example above, the SUPERCLASS binding is "from" B
and "to" A. An Association's type name is designed to be
read as if preceded by the possessive pronoun "my":
my SUPERCLASS is A
The "from" represents the base of the arrow in the diagram above, and "to" represents the arrowhead. To make it even clearer in the actual API, the "from" Binding is called the self binding, and the "to" Binding is called the referenced binding.
The extra care in terminology is needed because we have found that when coding it is easy to become confused about the "direction" of a particular association.
We may use XML to serialize our per-file ASTs.
We're also looking at s-expressions, JSON, and protocol
buffers as other options. This part of the design has
not yet been decided, and we're not currently storing
the ASTs in the index: instead we re-parse files on
demand.
Grok's graph format comes with a spiffy XML serialization format. This is useful for a variety of things:
Constructing unit tests. We use it for representing both the test data (by serializing a generated graph out as XML) and the "golden" test data against which we're comparing the generated graph.
Representing language-specific built-in types and objects. For instance, we hand-wrote XML to represent all of the JavaScript built-in objects and functions from the Ecma-262 specification. (Useful, for instance, for auto-completion of JavaScript properties.)
Generating Bindings and Associations from parsers/resolvers in languages other than Java. The XML format is what allows us to have language-specific indexers written in C++, Python, or whatever is most convenient for the language being added to Grok.
The format has not yet been stabilized. Here is a sample of what the XML looked like at one time:
<root>
<binding lang="JavaScript"
qname="foo.a"
sig="foo.a"
simplename="a"
type="GLOBAL_NAME">
<metadata file="google3/javatests/com/google/devtools/grok/javascript/testdata/decls_for_uses.js"
length="1"
offset="354"/>
</binding>
<binding lang="JavaScript"
qname="foo.a"
sig="foo.a:google3/javatests/com/google/devtools/grok/javascript/testdata/decls_for_uses.js:354"
simplename="a"
type="SCOPE">
<metadata file="google3/javatests/com/google/devtools/grok/javascript/testdata/decls_for_uses.js"
length="1"
offset="354"/>
</binding>
...
<association from="js:foo"
to="js:builtin:global"
type="PARENT_SCOPE"/>
<association file="google3/javatests/com/google/devtools/grok/javascript/testdata/decls_for_uses.js"
length="3"
offset="350"
to="js:foo"
type="REFERENCE"/>
<association from="js:builtin:global"
to="js:foo"
type="PROPERTY"/>
<association from="js:foo.a"
to="js:foo"
type="PARENT_SCOPE"/>
<association from="js:foo:google3/javatests/com/google/devtools/grok/javascript/testdata/decls_for_uses.js:339"
to="js:foo"
type="QNAME"/>
...
</root>
This graph fragment was generated from the following JavaScript code:
var foo = {};
foo.a = {
b: function() {
print('hi');
}
};
foo.a.b["c"] = 10;
The format is still under development. For examples of the latest format, you can look at the Grok Unit Tests' "golden" test data. For instance: //depot/google3/javatests/com/google/devtools/grok/javascript/golden/decls_for_uses.xml
We now use sstables, so this section of the original design document is obsolete and has been moved into its own document.
Our current schema is documented in the Grok Wiki.
Historically, creating middle-tier service APIs atop a rich data store like Grok's code graph poses challenging design problems. Relational databases have SQL, and Bigtables have MapReduce, both offering broad query flexibility. Adding a middle tier replaces this flexibility with any of several equally unsatisfying "service APIs". The most popular approaches are:
Deep copy, in which querying any object does a deep traversal of its dependencies and returns the entire sub-graph marshalled over the wire. The user can then "query" the graph returned by walking it programmatically. It is somewhat flexible at the cost of efficiency.
Fine-grained APIs, in which the service team slogs through an unending stream of requests from clients for APIs representing specific queries. This approach is machine-efficient but human-inefficient, and generates a great deal of interface churn.
Data Warehousing, in which the source data is extracted and given many indexes (typically a "cube"). If we were to replicate Grok's index into a separate graph-server with a different representation specific to static analysis, it would be a variant of the Data-Warehouse solution.
The Grok team does not particularly relish the idea of building a middle tier that frustrates potential clients, so we plan to take the following approach:
We will create a service layer and add common IDE operations (such as syntax highlighting a file, code formatting and refactoring) to the service layer as needed.
For any operations that are not generic to IDEs but may potentially be useful to multiple clients, we will consider accepting code submissions and integrating them into our service API.
We will offer a replica of our index that customers can use for MapReduces and other custom queries.
The initial set of services should include at least the following APIs:
This list covers a good starting subset of the code-browse and code-search facilities of a typical IDE. The "find all associations of type X" API is particularly powerful, as it lets you find callers, implementers, superclasses and subclasses, and other edges given some starting point. Repeated calls to that API can let you traverse the graph breadth-first or depth-first for short distances, e.g. to produce a browse hierarchy for some class or package.
For protocols, we initially expect to support Stubby and HTTP. The latter is necessary for clients that do not speak Stubby. We will include more detail about the protocol when we have more experience with implementing Grok services.
"SSO is problematic for command-line usage or authentication of an IDE plugin. OAuth might be a better choice for that case."
— Brian Slesinsky
Feel free to ping us at [email protected] if you have implementation suggestions or API ideas.
We have officially reached the point in the document where, as of July 20th 2008, we have very little idea how the design will unfold.
Implementing useful client-to-Grok interactivity will require
the notion of user "sessions" with Grok. It will be a big focus
for the Grok team in 2009.
Our initial launch client will be Grokweb. We have done one demo of Grokweb, although it is currently broken. Grokweb is a useful web-based code browser that incorporates elements of LXR, Sourcerer, Mondrian, (auto-generated) EngDocs, and read-only equivalents of many features provided by IDEs such as IntelliJ: class browsing, syntax highlighting, hover-over documentation for usage sites, and more.
In Q4 we plan to write (at very least) an Emacs plug-in for Grok. It will require designing a wire protocol. The plug-in will initially be for fetching last-crawled snapshot data to augment source editing in Emacs.
In time we expect to expand the plug-in to be able to communicate local file changes and even local buffer edits to Grok. This will require much tweaking and experimentation before we know exactly what we can release by Q1 2009. Stay tuned.
We will likely shuffle this directory organization around; for instance, the
language-specific indexers will move into a lang/ subdirectory.
google3/java/com/google/devtools/grok/bigtable/... — Bigtable serialization/deserializationgoogle3/java/com/google/devtools/grok/builder/... — Crawler/Indexer pipeline codegoogle3/java/com/google/devtools/grok/codegraph/... — Grok code graph memory model and APIsgoogle3/java/com/google/devtools/grok/deps/... — Blaze integrationgoogle3/java/com/google/devtools/grok/java/... — Java indexergoogle3/java/com/google/devtools/grok/javascript/... — JavaScript indexergoogle3/java/com/google/devtools/grok/testing/... — unit-test utilitiesgoogle3/java/com/google/devtools/grok/util/... — common utilitiesgoogle3/java/com/google/devtools/grok/web/... — Grokwebgoogle3/javatests/com/google/devtools/grok/... — Grok unit testsGrok's existing code is mostly for the indexing pipeline, and is written in Java. The serving clusters are entirely independent of indexing and may be written in C++; we have not yet decided.
TODO(stevey):
Grok is an intuitive idea that occurs to many developers independently. Despite being a popular idea, nothing even remotely like Grok exists at Google, because doing it "right" is a lot of tedious work.
To avoid doing this work, most code-search and code browsing tools (with the notable exception of IDEs) choose parsing techniques and intermediate representations (IRs) that are expedient to the problem at hand. Hence, LXR is great for cross-referencing but pretty much nothing else. GSearch is great for grep but not hierarchical browsing or contextual lookups. GTags knows a little about language-specific type systems but doesn't have a complete picture for anything but Java, and its index and protocol would both need a complete rewrite.
Grok is a lot of work, so we are trying to strike a balance between practicality and the "Right Thing". Striking this balance involves trade-offs that may seem remote at the moment, but when people start using Grok they will notice them right away.
As one example, we are faced with a short-term trade-off between accuracy and code coverage in Java, and we will probably go with accuracy, which means lots of Java code won't be indexed yet. We are making the opposite trade-off for JavaScript, which will have great code coverage but questionable accuracy (e.g. we may initially cross-pollinate unrelated projects in the symbol tables, resulting in spurious graph edges.) Both languages will improve in both dimensions over time, but we have to start somewhere.
We view Grok as a non-optional project. At the current rate of growth of Google's code base we'll have a billion lines of code by mid-2011. Developer productivity is negatively impacted as the code base grows larger and consequently more difficult to navigate and comprehend, and any productivity hit is multiplied by thousands of developers. It manifests as an invisible tax on launch efficiency: one that is already significant, albeit not easily measurable or quantifiable.
So although we're taking a practical "get something small done fast" tactical approach, we will not compromise on strategy. We will not, for instance, give up on formal parsing and turn to regexp-based pseudo-parsing, as most other indexers do.
Our target latency for the batch indexing is once per day. (This is actually an aggressive target; see Scaling the Build for an explanation.)
Our target latency for Grokweb page rendering (as seen from the browser) is 1000 ms. This isn't up to Google standards, but it would be a mis-prioritization to try to lower it this early in Grok's development.
Our 2008 target latency for interactive read-only lookups is 500 milliseconds, round-trip from the client. This includes use cases such as:
We will need to experiment with interactive use cases to determine reasonable latency targets. Anecdotally, users of Eclipse and IntelliJ seem to expect (and tolerate) delays of 500ms-1000ms between when they stop typing and when the source file's error messages are redisplayed. This seems like an achievable latency for Grok, but we will need to study it further in Q1 2009.
We plan to have up to 3 copies of our index at any given time:
The demand for static analysis support may be high enough for us to want a replica of our Bigtable for running mapreduces. TBD.
We cannot offer any hard uptime guarantees for Grok; the index may be unavailable for days or weeks. Developers should never be gated on Grok's availability. With that said, we will establish availability targets and try to hit them.
TODO(stevey): write me
TODO(stevey): write me
Our only plan here is to do lots of unit tests. We've been pretty good about it so far.
We do not currently have a load-test plan in place.
TODO(stevey): provide finer-grained estimates
TBD
If you have a keen eye for patentable inventions, and you see something in Grok that might qualify, please drop us a note.
TODO(stevey): talk to patent counsel
TODO(stevey): Find primary and secondary reviewers.
This section describes the major revisions of the document, and who did the review/signoff on it. The first time you submit the document to [email protected], also make sure to update designdoc-queue.html.
Whenever you add a new revision to the
document history, assign it a new revision class and add a new line to the
table below. rev0 is the original draft, the next versions
will be rev1, rev2, …. All text that
changed or was added with a new revision of the document should be
marked with
<div class="rev$n">…</div>
or <span class="rev$n">…</span>
tags.
| Date | Author | Description | Reviewed by | Signed off by |
|---|---|---|---|---|
| Jul 19, 2008 | Steve Yegge | Initial draft | TBD | TBD |
| … | … | Dummy entry demonstrating version highlighting (click if Javascript enabled) | … | … |
{kind=link}