 This is the approach we will most likely use for Grok,
if we cannot find a way to solve the problem using
local client builds (see next section).
This is the approach we will most likely use for Grok,
if we cannot find a way to solve the problem using
local client builds (see next section).
Status: Obsolete (as of 2010-08-16)
Steve Yegge <[email protected]> Last modified: 2010-08-16August 16th, 2010: This document used to be a section in the Grok Master Design Document. The issues discussed here are largely obsolete (or resolved). The bottom line is that Grok indexers are randomly sharded, the shards do a lot of redundant work, and we have processes in place to merge everything into a single global index. We will keep this approach until we move to incremental indexing.

As of July 2008, the google3 corpus has about 40,000 BUILD files
containing an average of 6 targets per file, yielding roughly 250,000
independently buildable targets. (Aug 16 2010:
There are over 100k build files in google3 now.)
The naïve approach is to build them sequentially in an arbitrary order. This works, but would take approximately 200 to 400 days to complete, based on best available estimates.
We have various options for parallelizing the build, each of which we touch on briefly here. Once we decide which approach to use, we'll create a design document for it.
Given N ~= 250,000 build targets and M ~= 200 indexer machines, one approach is to try to find ways to pre-cluster "related" targets such that different machines in M do different work.

For instance, if we found there were no dependencies between Java code and Python code at Google, we could partition the two languages to different sets of machines, and no work would be duplicated.
Although it's unlikely that there are any nontrivial independent sets in the Google code graph, it seems intuitively possible that there are clusterings that minimize the amount of duplication of building/indexing shared libraries.
Unfortunately the algorithms for doing this kind of clustering statically (Set cover, for instance) tend to be NP-hard with poor approximability.
The Grok team explored briefly a class of linear-time greedy algorithms that might produce a reasonable clustering of the Google build targets. The algorithms walk the build targets and subtract their flattened dependency graphs from the global set of targets, until some threshold is reached at which the remaining targets are grouped into a single cluster. One variant is to sort the input build targets by the size of their dependency lists, as a heuristic for the target's expected set-cover. Some experimentation suggested that we could get better results than random build-target assignment if we pursued this approach. We did not spend much time on it because dynamic solutions seem more promising.
If you are a graph-algorithms expert who wants to take a stab at his problem, we welcome your participation.
A more common approach to this problem class is to use a Work Stealing architecture.
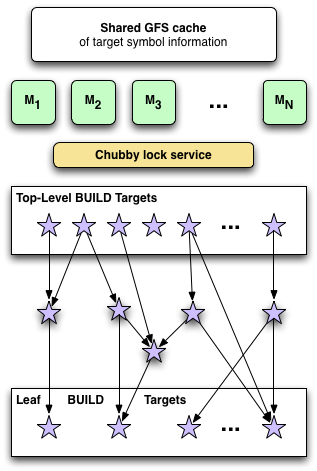
One such possible design has been proposed by our Grok team interns, sketched in the diagram to the left. The system is for a batch-based index build of a snapshot of the code base, and would need minor modifications to support incremental updates.
This is the approach we will most likely use for Grok,
if we cannot find a way to solve the problem using
local client builds (see next section).
This design uses a pool of N dedicated indexer machines M1 .. MN. The design aims to maximize overall machine utilization by not rebuilding any shared dependencies.
The workflow is roughly as follows:
"For scheduling, you may want to seriously consider not using Chubby. I'm not sure that it's well suited for the frequent update tasks that you seem to want to use it for. Since you're using Bigtable anyways, I'd probably look into building your state table there. It may be worthwhile to take a look at Workflow (which is what Evenflow and the Dremel importer uses) and Neptune (which is what the book scanning folks use) before rolling your own."
— Shuichi Koga
The machines {M} begin their polling at random positions in the top-level target list to help reduce lock contention. Each M repeats until no NOT_STARTED targets remain. The index is complete when all targets are COMPLETE.
Given enough machines, the wall-clock time for a full build of the code base from scratch should be about the same as the "long pole" build time: the longest clean-rebuild wall-clock time among the approximately 75,000 top-level build targets.
This proposed indexing approach is similar to the way the Forge distributed build system works. As such, it might be possible to use Forge for Grok's indexing. We spoke with the Forge team about it, and they felt that if indexing happens on Forge, it should be initiated on the local client by Blaze. This would result in something of a hybrid between the dynamic workload balancing in this section and local indexing discussed in the next section.
We have touched on two approaches to parallel build-target indexing using Borg clusters: static partitioning and dynamic workload balancing. A third approach is to push the indexing out to developer machines.
To differentiate the two, we will refer to the Borg-based approaches collectively as "centralized indexing", and indexing on developer machines as "local indexing".
Local indexing has some advantages over centralized indexing:
Grok's indexers would have a much lower contribution to the current machine-utilization Code Yellow. The parsing, resolving and graph construction would all happen on developer boxes. Only sending the graph information to our Bigtable would involve any corp or prod resources.
We would be using "guaranteed" builds: Grok's indexing process would only initiate after a successful developer build. Some projects are nearly impossible to build reliably from the trunk sources, which would make centralized indexing problematic. (One notorious example of such a project is the AdWords Frontend.)
Local indexing has easier access to local client modifications. When we do interactive Grok, some form of local indexing will be necessary. If we use centralized indexing, we would likely need a combination of Mondrian client snapshots and GTags local filesystem listeners to figure out the user's local symbols. It might be very difficult to achieve acceptable interactive latency using a fully centralized indexing model.
Local indexing also has its disadvantages:
Grok's symbol indexing can take up to several minutes for
a clean rebuild of a large project. The process could be
run asynchronously (with nice) after a successful
developer build, but it could still potentially be noticeable
to the developer. It would be quite unfortunate if the act of building
our productivity-enhancing code index were to diminish productivity.
If nobody is building a particular project, Grok would not index it. We would need an occasional full refresh of the Grok index using one of the centralized approaches.
Because developers build from specific client snapshots, we would be forced to deal with the code-versioning problem up front, rather than being able to defer it, which could push out our initial Grokweb deliverable.
We do not yet have much data on the impact our indexing pass would have on a normal build. The time varies by language, and we are still tuning the performance of our initial indexers. For a large top-level target, it could take several minutes. The indexing could be done asynchronously after the regular build finishes.

The Q3 2008 OKRs included mention of a continuous-build project that would archive pre-built versions of shared libraries. This proposed system could be a potential home for Grok's symbol-indexing jobs.
Another possibility might be to piggyback on the continuous unit-test build system, which uses essentially the same build-dependency information from Blaze.
The bottom-line takeaway is that indexing all of Google's code to Grok's specifications is a problem that must be parallelized.
If we fail to find a way to reuse an existing system to run Grok's indexers, we will establish our own pool of Borg jobs for now. Fortunately the indexers have simple inputs and outputs, so moving to a different parallelization scheme later should not be difficult.
Parallel indexing is one of the key design decisions we face, so if you have thoughts about it, please ping grok-discuss.